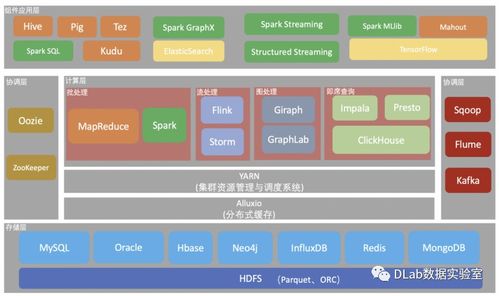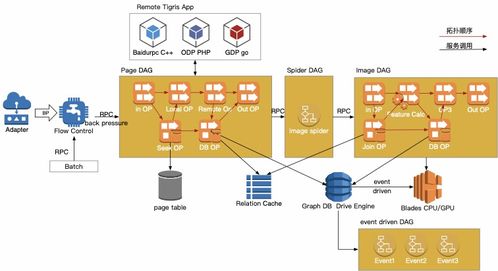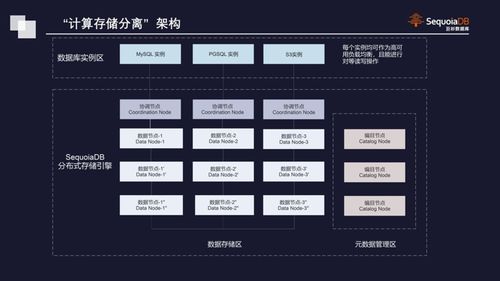
在銷售數據倉庫建立的第一步完成需求分析與架構規劃后,第二步是將其落地的核心工程階段。此階段聚焦于數據的物理遷移、結構化設計以及處理能力的構建,為后續的數據分析與決策支持奠定堅實基礎。本步驟主要包含四個關鍵環節:數據遷移、數據倉庫事務表設計、存儲過程設計,以及數據處理與存儲支持服務。
一、數據遷移:從源系統到數據倉庫的橋梁
數據遷移是將分散在各個業務系統(如CRM、ERP、訂單系統)中的歷史與增量銷售數據,抽取、清洗、轉換并加載(ETL過程)到數據倉庫中的過程。這是構建數據倉庫的“奠基”工程。
- 策略制定:需明確遷移范圍(全量/增量)、遷移頻率(實時/準實時/每日批處理)與數據一致性要求。對于銷售數據,初始通常需要一次全量歷史數據遷移,后續通過增量遷移保持同步。
- ETL/ELT流程開發:
- 抽取(Extract):從源系統安全、高效地獲取數據,需處理不同數據源(結構化數據庫、日志文件、API接口)的連接與讀取。
- 轉換(Transform):這是核心清洗環節。針對銷售數據,需統一商品編碼、客戶ID、日期格式;處理缺失值、異常值(如負銷售額);進行業務邏輯計算(如計算折扣后凈銷售額、毛利潤)。
- 加載(Load):將清洗轉換后的數據加載到數據倉庫的ODS(操作數據存儲)層或直接加載到維度模型中。
- 遷移驗證與回滾方案:必須建立嚴格的數據質量校驗規則(如記錄數核對、關鍵指標匯總比對),并準備應急預案,確保遷移過程可靠。
二、數據倉庫事務表設計:構建星型/雪花型模型
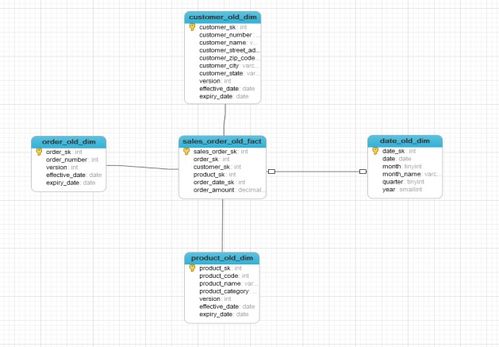
數據倉庫的表結構設計通常采用維度建模,以優化查詢性能和分析效率。對于銷售業務,最核心的是構建以“銷售事實表”為中心的星型模型。
- 事實表設計:
- 核心事務表:銷售訂單事實表。其主鍵通常為復合鍵,包含多個維度鍵。事實(度量)包括:銷售數量、銷售額、成本、折扣金額、稅費等可累加的數字指標。
- 事務粒度:每條記錄代表一筆訂單或一個訂單明細項,這是最細顆粒度,保證了最大分析靈活性。
- 維度表設計:圍繞事實表,設計一系列描述性維度表,提供分析視角:
- 時間維度:年、季度、月、日、節假日標志,是銷售分析最重要的切片維度。
- 產品維度:產品ID、名稱、類別、品牌、價格段等。
- 客戶維度:客戶ID、 demographics信息、客戶等級、所屬區域等。
- 渠道/店鋪維度:線上線下渠道、門店ID、地理位置、經理等。
- 員工維度:銷售員、客服等。
- 維度表應使用代理鍵(自增ID)與事實表關聯,以處理緩慢變化維(SCD)問題,例如客戶地址變更。
三、存儲過程設計:自動化與業務邏輯封裝
存儲過程在數據倉庫中扮演著“自動化引擎”和“邏輯容器”的角色,主要用于調度復雜的ETL任務和實現可重用的數據加工邏輯。
- ETL作業調度:創建存儲過程來封裝每個ETL步驟(如“抽取訂單數據”、“清洗客戶信息”),并通過作業調度工具(如SQL Server Agent, Apache Airflow)按依賴關系和時間順序自動執行,形成完整的數據流水線。
- 數據清洗與轉換邏輯:將復雜的清洗規則(如識別并標記異常交易)、多表關聯和計算邏輯(如生成月度銷售匯總中間表)編寫成存儲過程,提高代碼復用性和可維護性。
- 維度管理:編寫處理緩慢變化維(SCD)的存儲過程,例如當產品信息更新時,是覆蓋(Type 1)還是新增歷史記錄(Type 2)。
- 性能優化:通過存儲過程,可以更精細地控制事務邊界和批量操作,提升大數據量處理效率。
四、數據處理和存儲支持服務:確保系統健壯與高效
此部分是為整個數據倉庫提供穩定、高效運行的底層支撐環境與服務。
- 計算與處理服務:
- 根據數據處理量(日增量、歷史總量)和復雜度,選擇合適的計算資源(如高性能數據庫集群、大數據處理平臺如Spark)。
- 設計并實施合理的資源隊列和優先級策略,確保ETL作業、即席查詢和報表生成任務互不干擾。
- 存儲管理與優化:
- 分層存儲:明確數據倉庫各層(ODS、DWD明細層、DWS匯總層、ADS應用層)的存儲策略與生命周期管理(如明細數據保留7年,匯總數據永久保留)。
- 分區與索引:對大型事實表(尤其是銷售訂單表)按時間(如按月)進行分區,可極大提升查詢和維護效率。針對高頻查詢條件(如產品類別、區域)建立合適的索引。
- 壓縮與歸檔:對歷史冷數據實施數據壓縮,節省存儲空間;制定歸檔策略,將極少訪問的數據移至成本更低的存儲介質。
- 監控與運維支持:
- 建立監控體系,跟蹤ETL作業運行狀態、耗時、數據質量指標、存儲空間使用率和查詢性能。
- 設置告警機制,對作業失敗、數據延遲、空間不足等情況及時通知運維人員。
- 提供日常的數據維護服務,如索引重建、統計信息更新、存儲空間擴容等。
###
數據倉庫建立的第二步是將藍圖轉化為實體的關鍵構建階段。通過嚴謹的數據遷移確保數據資產完整、準確地入庫;通過科學的事務表設計(維度模型)構建易于理解和高效查詢的數據結構;通過高效的存儲過程設計實現數據處理流程的自動化和邏輯封裝;通過強大的數據處理和存儲支持服務保障整個系統穩定、高性能地持續運行。這四個環節環環相扣,共同構成了數據倉庫的“軀干”與“神經系統”,為后續的數據分析、報表展現和商業智能應用提供了純凈、統一、可靠的數據源。