在前兩篇關(guān)于數(shù)據(jù)庫(kù)存儲(chǔ)與索引技術(shù)的探討中,我們介紹了B+樹等傳統(tǒng)索引結(jié)構(gòu)及其在磁盤友好型場(chǎng)景下的優(yōu)勢(shì)。隨著大數(shù)據(jù)和實(shí)時(shí)寫入密集型應(yīng)用的興起,一種名為“日志結(jié)構(gòu)合并樹”(Log-Structured Merge-Tree,簡(jiǎn)稱LSM樹)的設(shè)計(jì)脫穎而出,它通過巧妙的“寫入優(yōu)化”思想,極大地提升了系統(tǒng)的寫入吞吐量。本文將深入剖析LSM樹的一個(gè)典型實(shí)現(xiàn)案例,并探討其如何作為核心引擎,支撐起現(xiàn)代數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)。
一、LSM樹核心思想回顧
LSM樹的核心設(shè)計(jì)哲學(xué)是將隨機(jī)寫入轉(zhuǎn)換為順序?qū)懭耄瑥亩浞掷么疟P(尤其是HDD)或新型存儲(chǔ)介質(zhì)的順序I/O高性能。其基本架構(gòu)通常包含以下關(guān)鍵組件:
- 內(nèi)存表(MemTable):所有寫入操作首先被追加到內(nèi)存中的有序數(shù)據(jù)結(jié)構(gòu)(如跳表、AVL樹)中,實(shí)現(xiàn)極快的寫入速度。
- 不可變內(nèi)存表(Immutable MemTable):當(dāng)MemTable達(dá)到一定大小閾值后,會(huì)轉(zhuǎn)換為只讀狀態(tài),成為Immutable MemTable,等待被持久化到磁盤。
- Sorted String Table(SSTable):Immutable MemTable中的數(shù)據(jù)被順序?qū)懭氪疟P,形成一個(gè)個(gè)不可變的、內(nèi)部有序的數(shù)據(jù)文件,即SSTable。每個(gè)SSTable還附帶一個(gè)稀疏索引(Bloom Filter等)以加速查詢。
- 合并(Compaction):隨著SSTable數(shù)量的增多,系統(tǒng)會(huì)定期將多個(gè)舊的、可能存在重復(fù)或已刪除鍵的SSTable合并成新的、更大的SSTable,并清理無效數(shù)據(jù)。這個(gè)過程是LSM樹后臺(tái)的核心操作。
二、經(jīng)典實(shí)現(xiàn)案例:LevelDB/RocksDB
LevelDB(由Google開發(fā))及其高性能分支RocksDB(由Facebook優(yōu)化)是LSM樹思想最著名、應(yīng)用最廣泛的開源實(shí)現(xiàn)。它們常被用作嵌入式鍵值存儲(chǔ)引擎,支撐著眾多大型分布式系統(tǒng)。
1. 數(shù)據(jù)組織:層級(jí)結(jié)構(gòu)
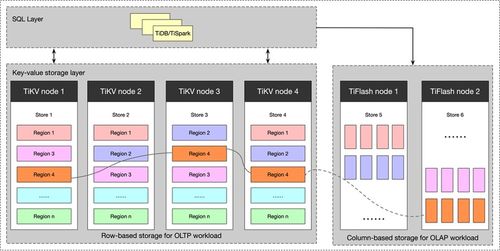
LevelDB/RocksDB采用了分層的SSTable組織方式(Leveled Compaction)。磁盤上的SSTable被組織成多個(gè)層級(jí)(L0, L1, L2...)。
- L0層:由Immutable MemTable直接刷盤生成,允許SSTable之間的鍵范圍重疊。
- L1及更深層:每層的數(shù)據(jù)量呈指數(shù)增長(zhǎng)(例如10倍),且同一層內(nèi)的SSTable鍵范圍互不重疊,且全局有序。這種結(jié)構(gòu)極大地優(yōu)化了范圍查詢的效率。
2. 關(guān)鍵流程
- 寫入流程:寫入鍵值對(duì) → 追加到WAL(Write-Ahead Log,用于崩潰恢復(fù)) → 插入MemTable → 返回成功。整個(gè)過程幾乎全是內(nèi)存操作和順序磁盤追加,速度極快。
- 讀取流程:查詢鍵 → 首先查找MemTable → 再查找Immutable MemTable → 最后從L0到最深層的SSTable中逐層查找。為加速查找,除了每層的文件元數(shù)據(jù)索引,還廣泛使用Bloom Filter來快速判斷一個(gè)鍵是否絕對(duì)不存在于某個(gè)SSTable中,從而避免大量不必要的磁盤I/O。
- 合并流程(Compaction):這是后臺(tái)持續(xù)進(jìn)行的核心任務(wù)。當(dāng)某一層的數(shù)據(jù)量超過閾值時(shí),會(huì)從該層選取一個(gè)或多個(gè)SSTable,與下一層鍵范圍有重疊的SSTable進(jìn)行多路歸并排序,生成新的、有序的SSTable寫入下一層,并刪除舊的輸入文件。這個(gè)過程有效控制了SSTable的總數(shù),并持續(xù)進(jìn)行數(shù)據(jù)整理與垃圾回收。
3. 優(yōu)勢(shì)與權(quán)衡
- 優(yōu)勢(shì):極高的寫入吞吐量;出色的空間放大率(特別是使用Leveled Compaction時(shí));為順序I/O優(yōu)化。
- 權(quán)衡:讀取操作可能涉及多次I/O(需要權(quán)衡內(nèi)存大小、BloomFilter精度和層級(jí)數(shù));寫入放大(Compaction過程中數(shù)據(jù)被反復(fù)重寫);在某些工作負(fù)載下可能產(chǎn)生較高的延遲毛刺(由后臺(tái)Compaction引起)。RocksDB針對(duì)這些權(quán)衡做了大量?jī)?yōu)化,如可調(diào)的Compaction策略、多線程Compaction、更精細(xì)的速率限制等。
三、作為數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)的引擎
LSM樹引擎(以RocksDB為代表)本身并非直接面向終端用戶的服務(wù),而是作為核心的“存儲(chǔ)引擎”或“數(shù)據(jù)內(nèi)核”,嵌入到更上層的、功能完備的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)中。其應(yīng)用模式主要體現(xiàn)在以下幾個(gè)方面:
1. 分布式數(shù)據(jù)庫(kù)/鍵值存儲(chǔ)的存儲(chǔ)層
許多著名的分布式系統(tǒng)使用RocksDB作為每個(gè)節(jié)點(diǎn)本地?cái)?shù)據(jù)的存儲(chǔ)引擎。例如:
- TiKV:TiDB分布式數(shù)據(jù)庫(kù)的分布式鍵值存儲(chǔ)層,使用RocksDB存儲(chǔ)Region數(shù)據(jù),支撐了TiDB強(qiáng)大的HTAP能力。
- CockroachDB:其每個(gè)節(jié)點(diǎn)的存儲(chǔ)層同樣基于RocksDB構(gòu)建。
- Apache Cassandra / ScyllaDB:這些寬列數(shù)據(jù)庫(kù)的本地存儲(chǔ)引擎也深受LSM樹思想影響,或直接集成RocksDB。
在這些系統(tǒng)中,LSM樹引擎負(fù)責(zé)高效的本地?cái)?shù)據(jù)持久化、排序和檢索,而上層服務(wù)負(fù)責(zé)分布式事務(wù)、一致性協(xié)議、數(shù)據(jù)分片、副本管理、SQL接口等。
2. 流處理與事件存儲(chǔ)
在Kafka或Pulsar等消息隊(duì)列中,需要持久化大量的有序消息日志。LSM樹順序?qū)懭氲奶匦苑浅_m合此類場(chǎng)景。例如,Apache Pulsar的“分層存儲(chǔ)”特性可以使用RocksDB來管理已消費(fèi)消息的索引和元數(shù)據(jù),實(shí)現(xiàn)高效的老數(shù)據(jù)卸載與檢索。
3. 時(shí)序數(shù)據(jù)庫(kù)(TSDB)
時(shí)序數(shù)據(jù)具有高并發(fā)寫入、按時(shí)間范圍查詢?yōu)橹鞯奶攸c(diǎn)。許多時(shí)序數(shù)據(jù)庫(kù)(如InfluxDB的存儲(chǔ)引擎Time Structured Merge Tree - TSM,其思想與LSM同源)或基于RocksDB構(gòu)建的時(shí)序數(shù)據(jù)庫(kù)方案,利用LSM樹高效處理時(shí)間序列數(shù)據(jù)的批量寫入和按時(shí)間窗口的壓縮合并。
4. 搜索引擎的倒排索引存儲(chǔ)
搜索引擎需要快速更新和合并倒排索引列表。LSM樹“先內(nèi)存后磁盤、定期合并”的模式,天然適合處理這種增量更新的索引數(shù)據(jù),能夠平衡索引的實(shí)時(shí)更新性與查詢性能。
四、
LSM樹通過其獨(dú)特的“以順序I/O換寫入性能”的設(shè)計(jì),成功解決了高吞吐寫入場(chǎng)景下的傳統(tǒng)B+樹瓶頸。以LevelDB/RocksDB為代表的實(shí)現(xiàn),通過層級(jí)化SSTable、Bloom Filter、可配置的合并策略等精巧設(shè)計(jì),將這一理論模型工程化、高性能化。如今,它已不僅僅是學(xué)術(shù)界的一個(gè)概念,更是現(xiàn)代數(shù)據(jù)處理與存儲(chǔ)基礎(chǔ)設(shè)施中不可或缺的“基石”組件。從分布式數(shù)據(jù)庫(kù)到消息隊(duì)列,從時(shí)序數(shù)據(jù)到搜索引擎,LSM樹引擎作為核心的存儲(chǔ)支持服務(wù),在幕后默默支撐著互聯(lián)網(wǎng)時(shí)代海量數(shù)據(jù)的實(shí)時(shí)寫入與可靠存儲(chǔ),是構(gòu)建高性能、可擴(kuò)展數(shù)據(jù)系統(tǒng)的關(guān)鍵選擇之一。理解其原理與實(shí)現(xiàn),對(duì)于設(shè)計(jì)和優(yōu)化數(shù)據(jù)密集型應(yīng)用至關(guān)重要。